|
International Journal The World Astrology Review, No 9 (57), September 30, 2006 Астрология и Информационные технологии Система идентификации субъектов по астрономическим данным на момент рожденияЕвгений Луценко (Краснодар, Россия), Александр Трунев (Торонто, Канада), Владимир Шашин (Санкт-Петербург, Россия)Как известно, существует несколько астрологических систем, предназначенных для описания карты рождения. Эти системы различаются между собой набором реальных и фиктивных планет, способами построения астрологических домов, смысловой интерпретацией аспектов и положений планет в домах и знаках. Главным недостатком существующих систем является то, что каждый астрологический прогноз, по сути, уникален, поэтому астрологию часто относят к искусству предсказания, а не к науке в обычном понимании. При этом всегда остается вопрос, насколько верным является астрологический прогноз в отношении данного субъекта. В последнее время была разработана принципиально новая система идентификации субъектов по данным рождения, основанная на системно-когнитивном анализе [1]. Эта система отличается от обычных астрологических моделей тем, что карта рождения не интерпретируется, а идентифицируется по ряду признаков и категорий, путем сравнения с базой данных, включающей описание характера и ключевых событий жизни множества реальных субъектов. Идентификации данных осуществляется на основе системы искусственного интеллекта ЭЙДОС [1]. В результате идентификации каждый субъект получает индивидуальное описание, содержащее классы событий и категорий с указанием вероятности их реализации. В данной работе этот метод анализа использован для идентификации множества субъектов, описанных в астрологической базе данных [2]. В проделанном исследовании не использовались никакие астрологические правила интерпретации. Статистические закономерности и взаимосвязи выявлялись в процессе обработки данных системой искусственного интеллекта ЭЙДОС путем сравнения карт рождения и жизнеописаний субъектов. Тестовые примеры убедительно демонстрируют эффективность системы по распознаванию определенных классов субъектов. Таким образом, впервые экспериментально показана статистическая значимость утверждений, основанных на сопоставлении множества карт рождения. Как было установлено, наилучшим образом идентифицируются субъекты, рожденные и проживавшие в среде, из которой были взяты исходные данные задачи.1. Система искусственного интеллекта ЭЙДОССистема ЭЙДОС является одним из элементов предлагаемого решения проблемы и достижения цели данной работы, т.к. она обеспечивает решение следующих задач: 1. Синтез и адаптация семантической информационной модели предметной области, включая активный объект управления и окружающую среду. 2. Идентификация и прогнозирование состояния активного объекта управления, а также разработка управляющих воздействий для его перевода в заданные целевые состояния. 3. Углубленный анализ семантической информационной модели предметной области. Таким образом, система ЭЙДОС является инструментарием, решающим проблему данной работы. Синтез содержательной информационной модели предметной области Для разработки информационной модели предметной области необходимо владеть основными принципами ее когнитивной структуризации и формализованного описания. Синтез содержательной информационной модели включает следующие этапы: 1. Формализация (когнитивная структуризация предметной области). 2. Формирование исследуемой выборки и управление ею. 3. Синтез или адаптация модели. 4. Оптимизация модели. 5. Измерение адекватности модели (внутренней и внешней, интегральной и дифференциальной валидности), ее скорости сходимости и семантической устойчивости. Идентификация и прогнозирование состояния объекта управления, выработка управляющих воздействий Данный вид работ включает: 1. Ввод распознаваемой выборки. 2. Пакетное распознавание. 3. Вывод результатов распознавания и их оценку. Углубленный анализ содержательной информационной модели предметной области Углубленный анализ выполняется в подсистеме "Типология" и включает: 1. Информационный и семантический анализ классов и признаков. 2. Кластерно–конструктивный анализ классов распознавания и признаков, включая визуализацию результатов анализа в оригинальной графической форме когнитивной графики (семантические сети классов и признаков). 3. Когнитивный анализ классов и признаков (когнитивные диаграммы и диаграммы Вольфа Мерлина). 4.2. Обобщенная структура системы ЭЙДОС Данной обобщенной структуре соответствуют и структура управления и дерево диалога системы - таблица 1. Таблица 1 – Обобщенная структура системы ЭЙДОС (версии 12.5)
Подробнее подсистемы, режимы, функции и операции, реализуемые системой ЭЙДОС, описаны в монографии [1]. 2. Исходные данные задачиОсновным источником астрологической базы данных, подготовленной для системы ЭЙДОС, является Lois Rodden’s AstroDatabank (см. www.astrodatabank.com). Эта база содержит жизнеописание знаменитостей и простых людей, проживавших (или проживающих) в США. Достоинством этой базы данных является то, что, все события жизни классифицированы, а все профессиональные и иные категории упорядочены. На первом этапе данные были конвертированы в формат баз данных JDataStore фирмы Borland. Затем данные были тщательно отсортированы, с использованием SQL запросов и специальных функций на языке Java. В результате были получены астрологические и биографические данные для 20007 уникальных персон и 16360 записей событий, происходивших с ними. Для них всех с помощью библиотеки швейцарских эфемерид (см. www.astro.com) были вычислены координаты небесных тел (долгота и широта в градусах и расстояние в астрономических единицах). Для записей с точным временем вычислялись куспиды астрологических домов в системе Плацидуса, а также звездные стоянки Луны - накшатры (использовалась система из 27 стоянок). В анализе были использованы эфемериды следующих небесных тел: Солнца, Луны, Меркурия, Венеры, Марса, Юпитера, Сатурна, Урана, Нептуна, Плутона и Хирона. Следующим шагом является сортировка персон по категориям. В результате было получено XML дерево категорий исходной базы данных. Для этой цели была написана процедура, позволяющая безошибочно изменять категории, сортируя его. Далее база данных была полностью экспортирована в формат Excel, а из него в формат интеллектуальной системы ЭЙДОС. Архив исходных данных в формате Excel доступен по адресу: http://astro.proforums.ru/tmp/abank.rar. Отметим, что работа с категориями продолжается и в настоящее время, поэтому архив обновляется и пополняется по мере пополнения исходной базы данных.3. Измерение адекватности моделиМодель тестировалась в три этапа. На первом этапе из числа данных было выделено 1000 карт, по которым определялись параметры схожести/различия. При этом из 11033 категорий было отсортировано 500 наиболее представительных (категория представлена в БД не менее 30 раз). Результаты тестирования размещены в архивах по адресу http://lc.kubagro.ru/1/astr10.rar. В этом примере синтез модели был выполнен на данных 19007 респондентов, а идентификация на 1000 тех, данные которых не использовались при синтезе модели. Идентификация каждого респондента - это его сравнение с каждым из 500 классов по тем из 532 признаков, которые были обнаружены у него (справочник астропризнаков располагается по адресу http://lc.kubagro.ru/astrolog/scales/priz_per.htm). Респондент считается идентифицированным правильно, если он был отнесен системой к классу, к которому он действительно относится. Средневзвешенная по всем классам адекватность модели составляет в этом примере 68.71%. Есть классы, по которым достоверность очень высокая, но есть и такие по которым она невысокая или низкая. По этим данным были определены семантические сети астрономических параметров - астропризнаков. Их архив находится по адресу http://lc.kubagro.ru/astrolog/klas-att/page_01.htm . Анализ семантических сетей астропризнаков позволяет сделать следующие выводы:
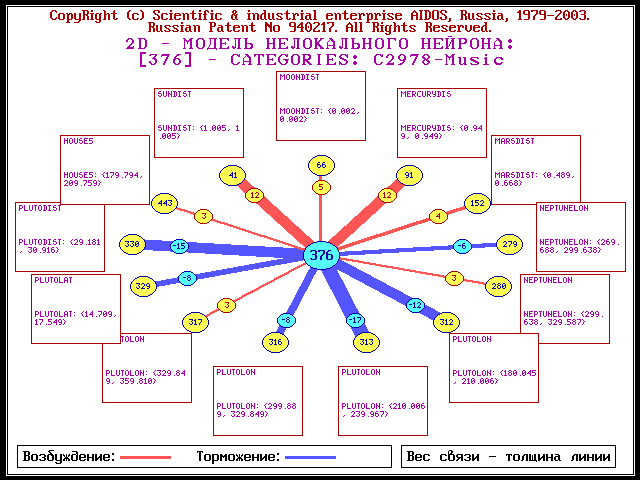
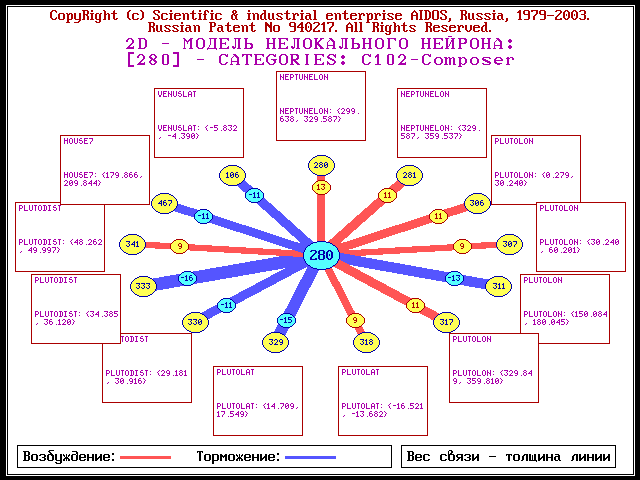
В силу идеологии проводимого исследования каждой из 500 категорий можно сопоставить нелокальный нейрон, возбуждение и торможение которого позволяет определить набор астропризнаков, оказывающих влияние на данную категорию. Диаграммы нелокальных нейронов размещены по адресу: http://lc.kubagro.ru/astrolog/Neuron/page_01.htm. Например, нейрон категории МУЗЫКА, согласно полученным результатам, возбуждается под влиянием 5 дома, расстояния до Солнца, Луны, Меркурия и Марса, но испытывает торможение под влиянием Плутона - рис. 1. Влияние Нептуна является смешанным. Отметим, что влияние расстояния до небесных тел было обнаружено и в других исследованиях [3]. В астрологии это соответствует влиянию аспектов [4]. Тот факт, что музыка находится в связи с 5 домом, Солнцем и Меркурием было известно астрологам уже во времена Птолемея. Интересно, что близкая к музыке категория КОМПОЗИТОР находится в связи с Нептуном (возбуждение) и Плутоном (торможение) рис. 2.Рис. 1. Модель нелокального нейрона категории МУЗЫКА
Рис. 2. Модель нелокального нейрона категории КОМПОЗИТОР
На втором этапе синтез модели был выполнен на данных 15007 респондентов, а идентификация осуществлялась для 5000 карт, случайно отобранных из начальных данных задачи и не использовавшиеся при синтезе модели. Результаты содержатся в архиве по адресу: http://lc.kubagro.ru/1/astr13.rar . Затем были сгенерированы 5000 случайных анкет, в которых астропризнаки являются случайными и принадлежность к категориям тоже случайная. Эти случайные данные идентифицировались на основе модели, синтез которой был осуществлен с использованием 15007 анкет, сгенерированных случайным образом. Результаты этого теста содержаться в архиве http://lc.kubagro.ru/1/astr14.rar . Сравнивая два теста, можно отметить следующее: уровни сходства конкретных объектов с классами в случайной модели значительно ниже, чем в обычной модели, как и уровни достоверности идентификации и внешняя валидность. Очевидно, что эти различия полностью обусловлены наличием зависимостей между астропризнаками и принадлежностью респондентов к различным категориям. В то же время необходимо отметить, что эта разница различна для различных категорий: для одних она очень большая, для других меньше, а для третьих практически отсутствует. В последнем тесте было выбрано 5000 карт, каждая 4-я в исходном массиве, синтез модели осуществлялся на основе 15007 анкет, которые не использовались при идентификации. Результаты содержаться в архиве: http://lc.kubagro.ru/1/astr16.rar . Результаты тестов на двух выборках из исходных данных согласуются друг с другом.На третьем этапе были идентифицированы все 20007 карт, см http://lc.kubagro.ru/1/astr15.rar или http://trounev.com/uploads/a15/ . Эти тесты показывают, что СК-анализ существенно отличается от просто статистики, в которой поиск корреляций между астропризнаками и принадлежностью к категориям осуществляется для отдельных респондентов. Типизация или обобщение, реализуемое в методе СК-анализе, является методом выделения сигнала из шума, аналогичным многоканальной системе с дублированием сообщения на многих датчиках или во времени. Интегральная мера сходства в СК-анализе между конкретным образом объекта (в нашем случае респондента) и обобщенным образом класса (категории), т.е. информационное расстояние, также одновременно является фильтром от белого шума. При этом различные астропризнаки имеют различный вес, как для дифференциации классов между собой, так и для идентификации респондентов с каждым из них. Зависимости выявляются уже между образом конкретного респондента и обобщенными образами классов (категорий), так и между классами или между самими астропризнаками. Этот подход существенно отличается от статистики. Проведенное исследование позволяет утверждать, что эти зависимости существуют, и что СК-анализ позволяет их выявить, изучить и использовать для решения задач идентификации (прогнозирования) и поддержки принятия решений. Особенно наглядно это видно при сравнении и сопоставлении реальной модели со случайной, аналогичной по размерностям справочников классов и признаков, а также объему обучающей выборки. Отметим также, что отношение сигнал/шум различно для различных обобщенных категорий и различных, конкретных респондентов, в результате чего некоторые из них идентифицируются очень хорошо, другие же гораздо хуже или практически на уровне случайного угадывания. 4. Дополнительные результаты и обсуждениеМодель тестировалась также на группе независимых респондентов, анкеты которых не были включены в исходную базу данных. Группа была подобрана так, что в нее входили люди, имеющие различные профессии и проживающие в разных странах - России, США, Канаде, Израиле и Германии. Как оказалось, наилучшим образом идентифицируются профессионалы, проживающие в англоязычных странах, т.е. субъекты, похожие на тех, чьи биографии были использованы при формировании первичной БД. Таким образом, установлено, что существуют региональные различия в проявлении индивидуальных признаков, что и выявилось в процессе тестирования представителей разных народов и культур. Некоторые примеры идентификации приведены в таблице 2. Знаком + отмечены категории, реально наблюдающиеся у нативов. Следует отметить, что профессиональные категории, как правило, имеют более низкий вес, чем другие категории, иначе говоря, человек проявляется в жизни, прежде всего, как человек, а не как представитель профессии. Тем не менее, даже при низком проценте сходства, попадание получается довольно точное.Например, Ingrid (см. таблицу 2) в молодости работала клерком в крупной компании, затем секретарем резидента компании. Ее первое замужество с известным греческим бизнесменом закончилось разводом. Затем она получила специальность терапевта (вторая категория в ее тесте). В 1999 году она выиграла огромную сумму денег в казино в Сингапуре (последняя категория в ее тесте).Irwin работал клерком и секретарем в крупной юридической компании по продаже зданий и сооружений для коммерческого использования (первые две категории в его тесте). Он развелся с женой, чтобы начать отношения с дочерью мультимиллионера (третья категория в его тесте). В молодости он играл в хоккей, был чемпионом в составе команды (последняя категория в его тесте). В возрасте 5 лет Jessica пережила ужасное событие - на ее глазах застрелили отца (первые две категории в ее тесте), она была королевой красоты (третья категория в ее тесте), была моделью в компаниях, производящих спортивную одежду (последняя категория в ее тесте) .Patricia начинала свою карьеру как балерина (последняя категория в ее тесте), потом как танцовщица. После травмы ноги она долгое время находилась на содержании семьи (вторая категория в ее тесте), пережила психоз и депрессию, короткое время была зависима от наркотиков, занималась продажами зданий, вышла замуж по совету отца, который обещал подарить ей на свадьбу миллион долларов (первая категория в ее тесте). Эти примеры показывают, что профессионалы, проживающие в Канаде и США, могут быть довольно точно идентифицированы с помощью использованной базы данных. Главным недостатком модели является грубое разбиение входных признаков модели - см. http://lc.kubagro.ru/astrolog/scales/priz_per.htm. Действительно, положение небесных тел по параметру долготы определяется с точностью до знака Зодиака. Более тонкое разбиение может значительно улучшить предсказательную силу модели. Представленная система идентификации нуждается в доработке в каждом отдельном случае, однако, показанные примеры убедительно демонстрируют, что астрология уже очень скоро может оказаться в ряду естественных наук, а астрологи и психологи получат новый мощный инструмент исследования человеческих судеб.Ссылки |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
{kind=link}